FileMaker Image-to-Text with Llama3.2-vision
Extracting Text From Images with a Self-Hosted LLM
Part of the FileMaker Pro series

Last week, Meta released the LLama3.2-vision models, adding image recognition to the existing v3.2 text models. GenAI with image-to-text has been out for a while now, but what’s new here is just how optimized and lightweight the models are. The smaller 11b (11 billion parameter) model is only 7.9Gb and can easily run on regular hardware, without the need for an expensive GPU.
In this guide, I’ll be building on a previous post about integrating with the original text model using FileMaker Pro and Ollama. Now that the vision model is out, I wanted to update the app to send images from a container field in FileMaker and share a copy of the finished app.
Running Llama3.2-vision Locally
Start out by installing the Ollama desktop app and opening it. You should see a llama icon in the menu bar. Then open up the terminal and run:
ollama run llama3.2-visionYou’ll see several files download the first time you run the model. Once the download is finished, the model will begin running and you can chat with it directly from the terminal!
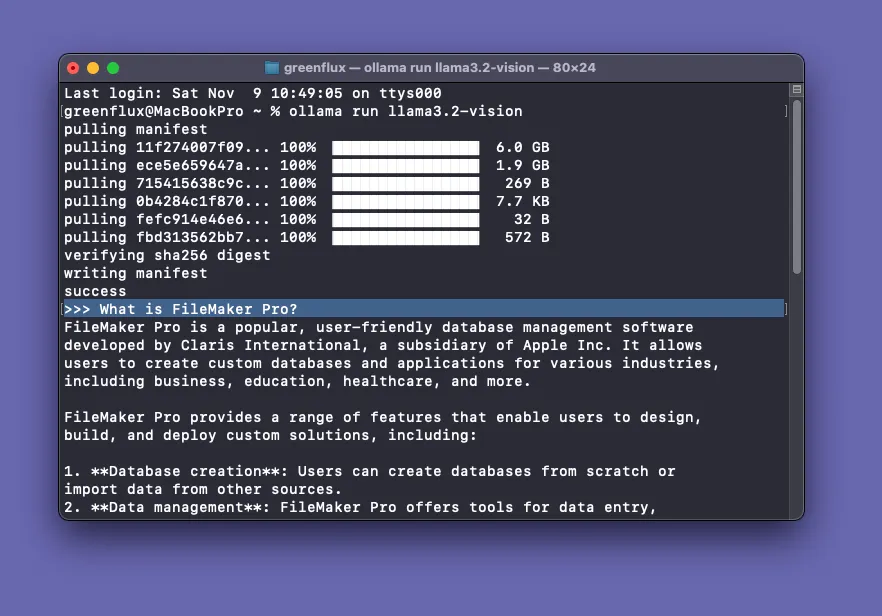
To include an image with a prompt, just drag a file into the terminal and it will add the file path!
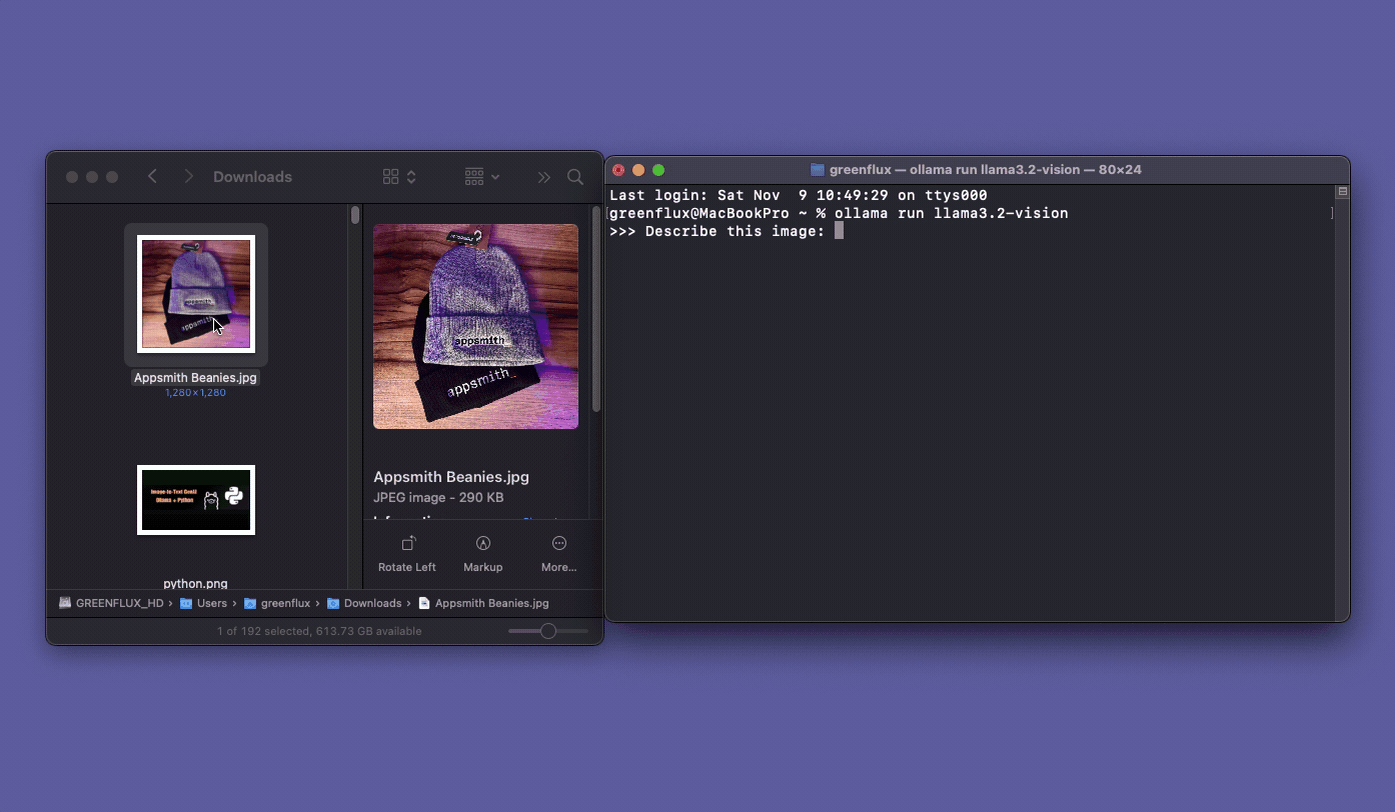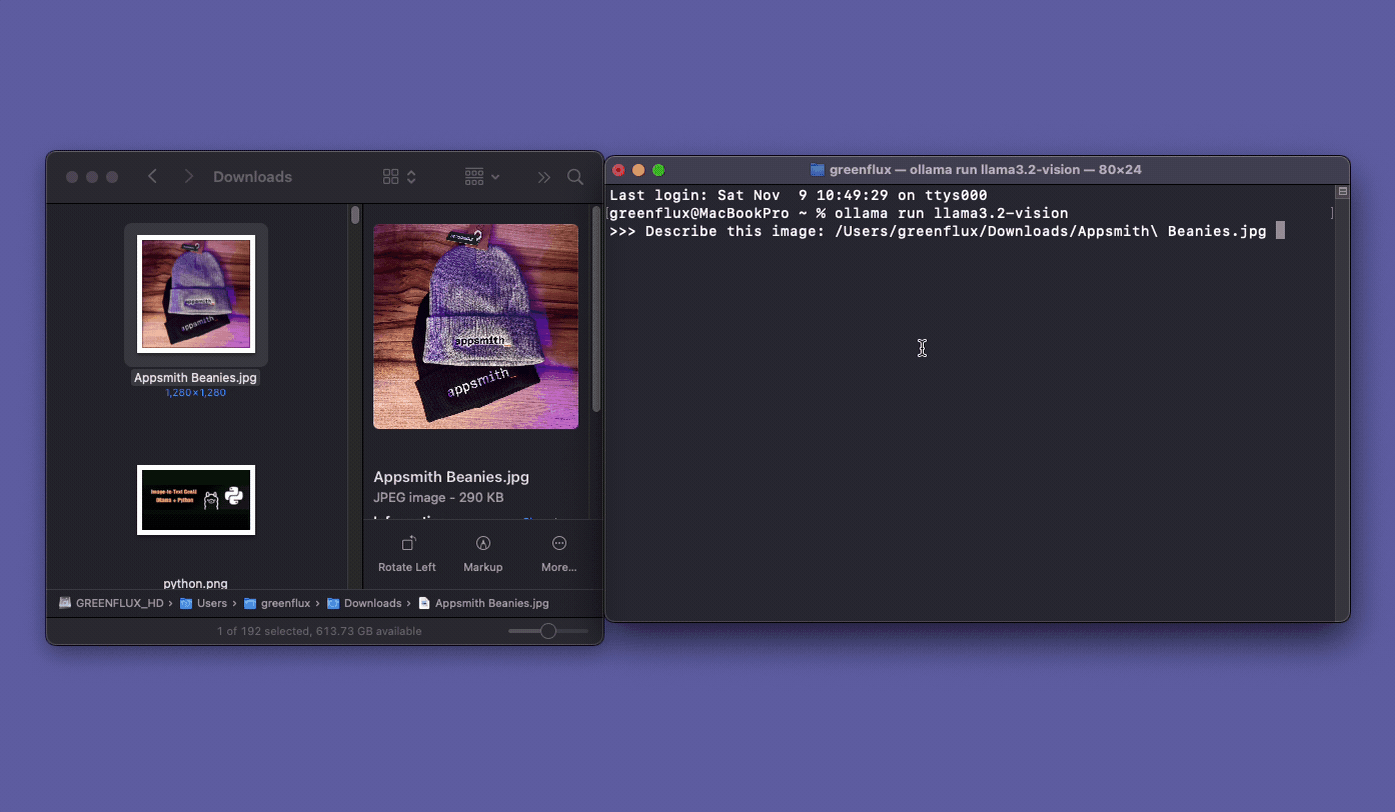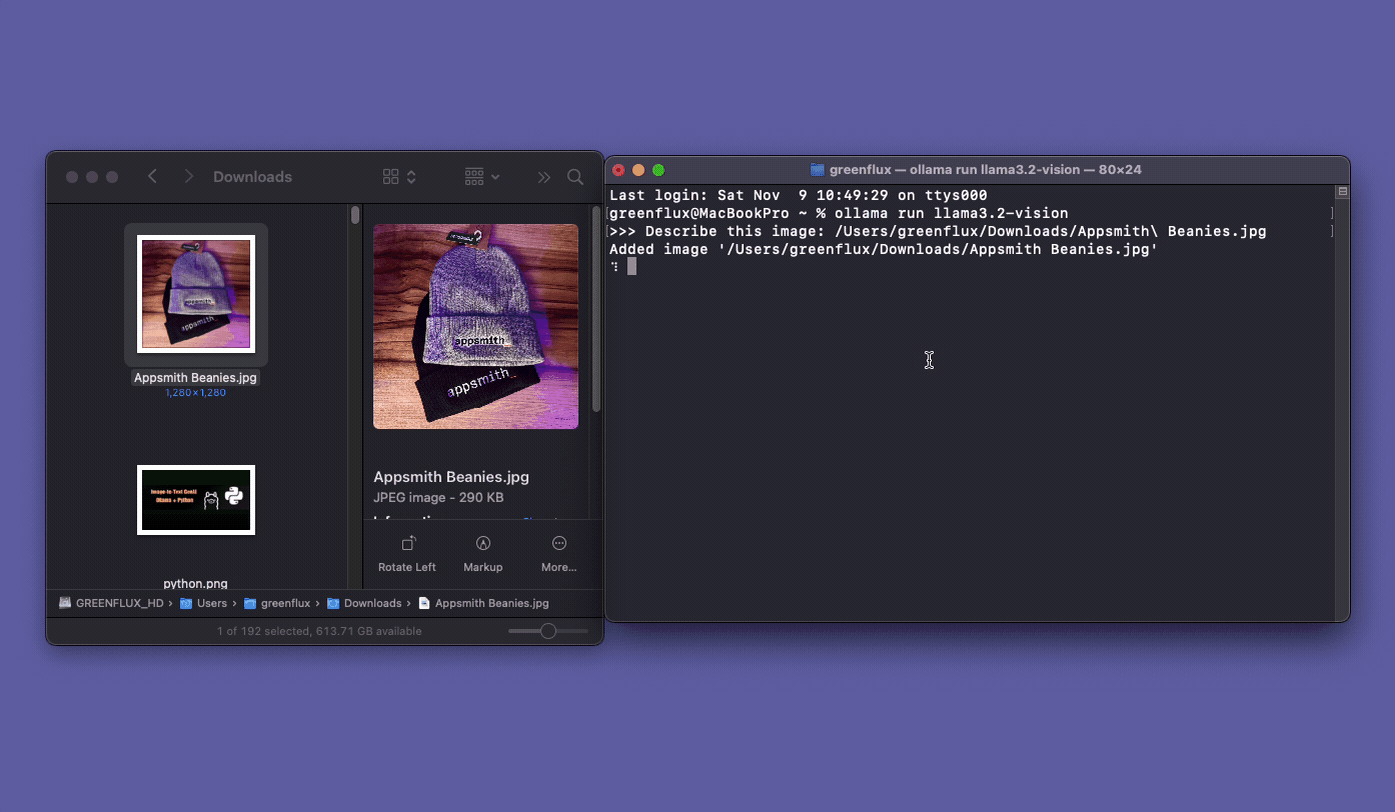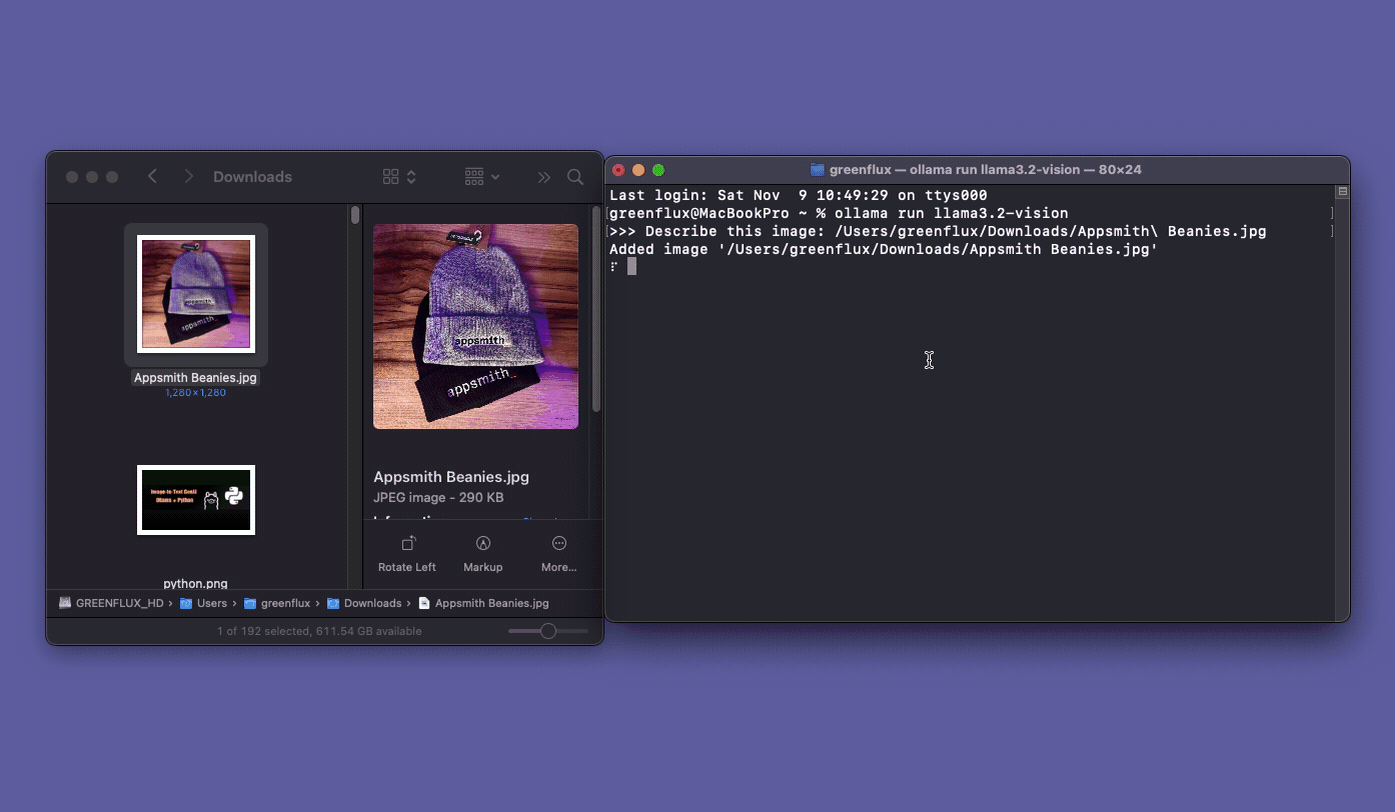
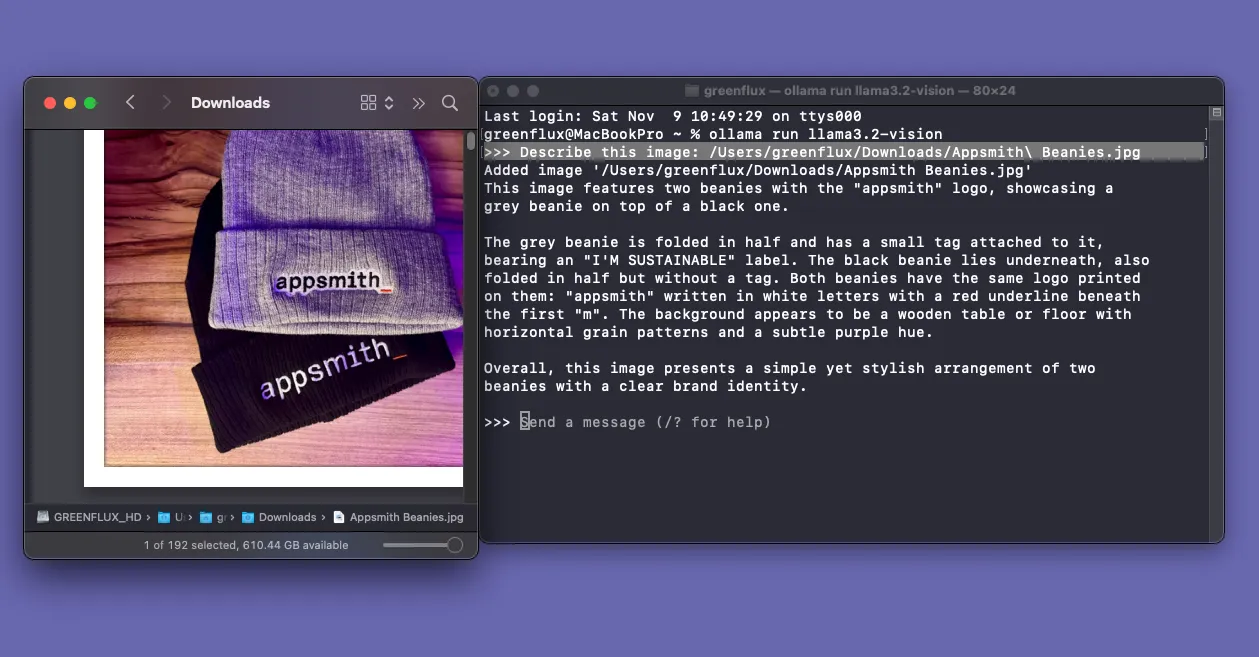
Sending Image Prompts From FileMaker
When the Llama3.2-vision models were released last week, the first thing I did was pull up the FMP chat app I made with the regular text model. Once I had the new model downloaded and running, it only took 2 minutes and a few small changes from the original FMP chat app, to start prompting with images. Since most of the steps are explained in the original tutorial, I’ll just be sharing the final, updated solution here.
Updated Script
Set Variable [ $image; Value:Base64Encode ( OllamaChat::image ) ]
Set Variable [ $body; Value:JSONSetElement ( "{}" ;
["stream" ; "false" ; JSONBoolean ];
["model" ; "llama3.2-vision" ; JSONString ];
["prompt" ; OllamaChat::Prompt ; JSONString ];
["images" ; "[\"" & $image & "\"]" ; JSONArray ]
) ]
// Show Custom Dialog [ Message: $body; Default Button: “OK”, Commit: “Yes”; Button 2: “Cancel”, Commit: “No” ]
Insert from URL [ $responseJSON; "http://localhost:11434/api/generate"; cURL options: "--header \"Content-Type: application/json\" --
data @$body" ]
[ Select; No dialog ]
Set Field [ OllamaChat::Reply; JSONGetElement ( $responseJSON ; "response" ) ]Updated UI and Database
- Added
OllamaChat::image(container field)
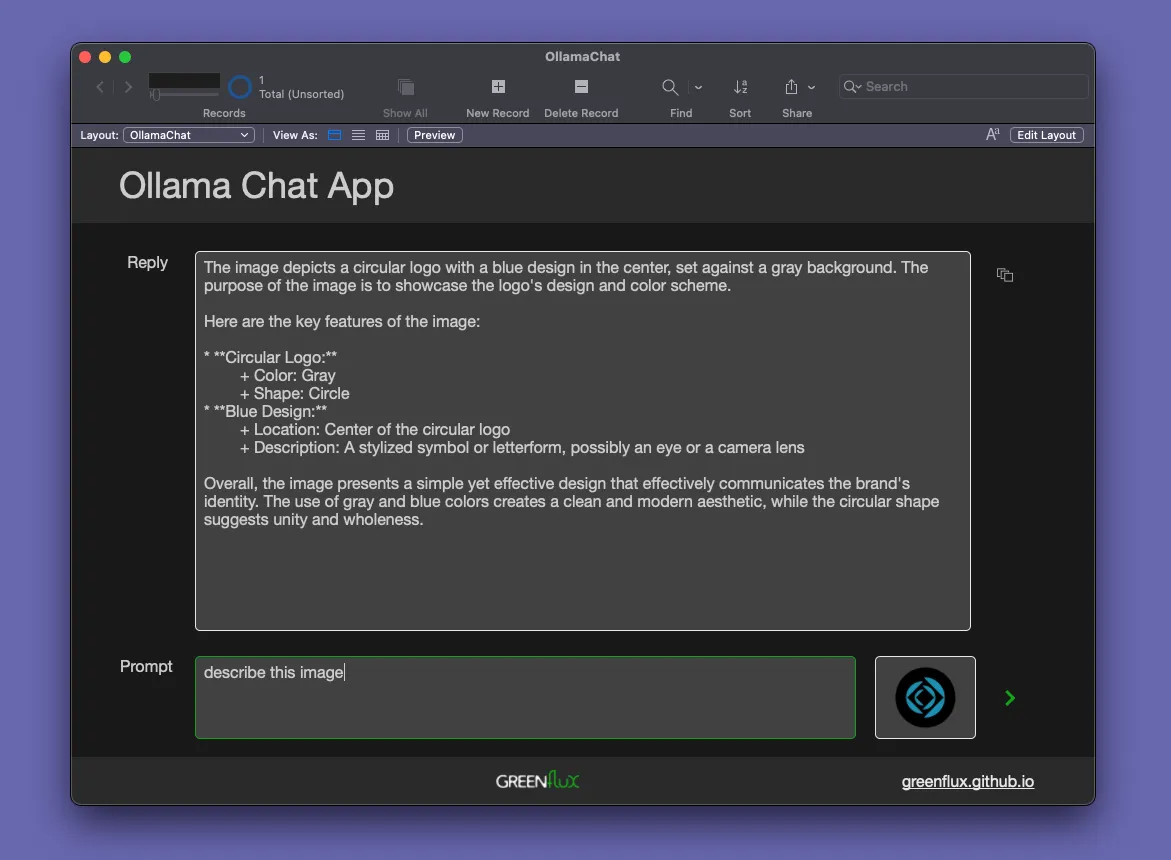
Link to app: FileMaker Experiments > OllamaChat
Conclusion
Newer multi-modal LLMs have advanced and been optimized to run on regular hardware, enabling new use cases and integrations, like image-to-text processing in FileMaker Pro. By hosting the model locally with Ollama, you can build AI integrations with image recognition, and avoid the privacy and security issues that come with web based services. This can also be a more cost effective solution, and it runs completely offline.
What’s Next?
From here, you can work on different prompts for describing images, extracting text, classifying images, or detecting certain types of content.
Got an idea for a new use case? Drop a comment below!
Also, I’d love to hear from others about how this performs on newer hardware. It takes at least a full minute or two on my laptop. How does it perform on a higher-end desktop with a dedicated GPU and more RAM?