Image-to-Text Extraction with Llama3.2-vision and Python
Local and Offline Image Processing Made Easy With Ollama
Part of the Python Tutorials series

Generative AI for image-to-text has been out for a while now, so we’ve all seen how well it can extract text compared to traditional OCR (optical character recognition). Sure, it can hallucinate, but OCR isn’t perfect either. If you’re just looking to extract text from an image, AI a much better solution, especially when the structure of the text is different in each image.
Web-based AI services can get expensive fast though, especially when uploading lots of image. Not to mention the privacy concerns your company may have about sending images to a 3rd party that might use them on training the model. Then there’s the whole VPC and firewall issue, if working in a larger enterprise. In cases like this, the best approach is to self-host and run an LLM locally to process the images within your own network.
This guide will cover:
-
Using Ollama to run the Llama3.2-vision model locally
-
Generating Text from Images via the terminal
-
Prompting the LLM from a Python script
-
Looping through images in a directory to output text
Let’s get prompting! 🤖
Llama3.2-vision
Released just last week, Llama3.2-vision is a collection of instruction-tuned image reasoning generative models in two different sizes:
11b: 11 billion parameters, 7.9Gb
90b: 90 billion parameters, 55Gb
And the 11b model is light-weight enough to run on a regular desktop or laptop, completely offline, and with full image recognition capabilities! This model has been distilled to a manageable size to work on lower power hardware, and yet still has great accuracy and decent performance with minimal RAM or GPU.
You’ll probably need at least 12Gb of RAM to have enough for the 7.9Gb model plus anything else running, but 16Gb is pretty common these days. For this guide, I’m running this on my M1 Macbook with 16Gb of RAM and it runs fine, although it could be a little faster.
Ollama Desktop App
The easiest way to get Llama3.2-vision running locally is Ollama, a desktop app for Mac, Windows and Linux, for downloading various models and run them locally on any hardware.
Start out by downloading Ollama for your OS. For this guide, I’ll be using MacOS, but most of the instructions should be the same for Windows or Linux, once you have Ollama running. Unzip the Ollama.app file, then drag it to your Applications folder to install it.
Running a model in Ollama
Once installed, open up the Ollama app and approve the permission request on first open. You’ll notice a new llama icon in the menu bar, with a single option to Quit Ollama.
There’s no other GUI— everything else is done from the terminal.
Open up a terminal and run this command:
ollama run llama3.2-visionThe first time you run it, you’ll see several files download before the model starts up. The smaller 11b (8Gb) model will download by default.
Once downloaded, the model will run automatically, and you’ll be presented with a prompt to start a chat.
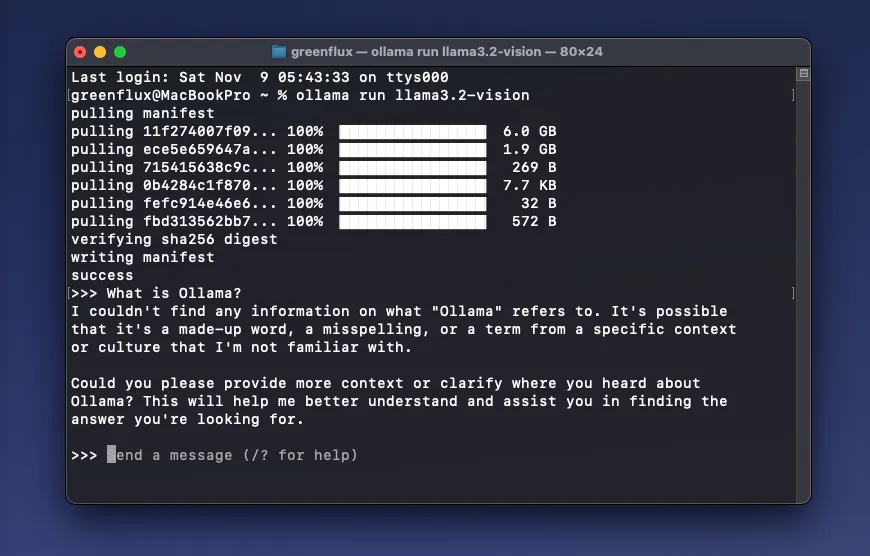
Next, try dragging an image into the terminal to add it’s path, then ask a question about the image.
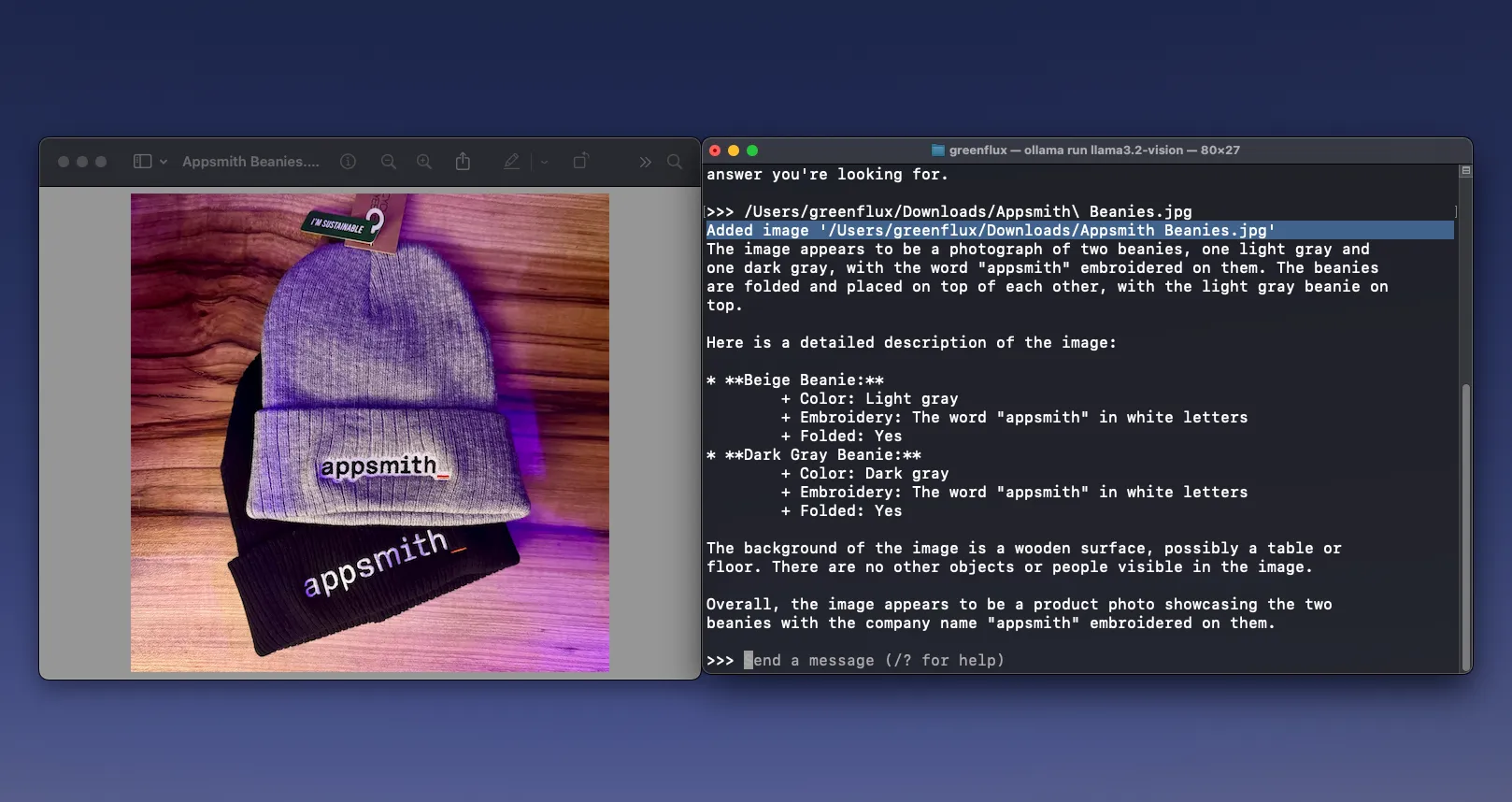
It may run a little slow on older hardware, but the fact that this works locally and offline is still pretty impressive. And it’s free! So if you have a large amount of images to process, everything can be done on your own machine, with no worries about AI subscription costs, ISP data caps, or privacy and security.
Prompting From A Python Script
Next, fire up your favorite text editor or Python IDE. For this guide, I’ll be using Visual Studio Code.
First, we’ll just write a simple script to send a test prompt to the LLM and print the response to the console.
import requests
endpoint = "http://localhost:11434/api/chat"
model = "llama3.2-vision"
def send_text_prompt(prompt):
payload = {
"model": model,
"stream": False,
"messages": [
{
"role": "user",
"content": prompt
}
]
}
response = requests.post(endpoint, json=payload, headers={"Content-Type": "application/json"})
return response.json().get('message', {}).get('content', 'No response received')
prompt = "What are the key components of a machine learning model?"
response = send_text_prompt(prompt)
print("Model Response:", response)Name the file send_text_prompt.py, and save it to a new folder where we can also add images for processing. Then, open up a new terminal window. Be sure to leave the first terminal window with Ollama open and running.
Navigate to the new folder, set up a virtual environment, and install requests:
python3 -m venv env
source env/bin/activate
pip install requestsThen run the file:
python3 send_text_prompt.py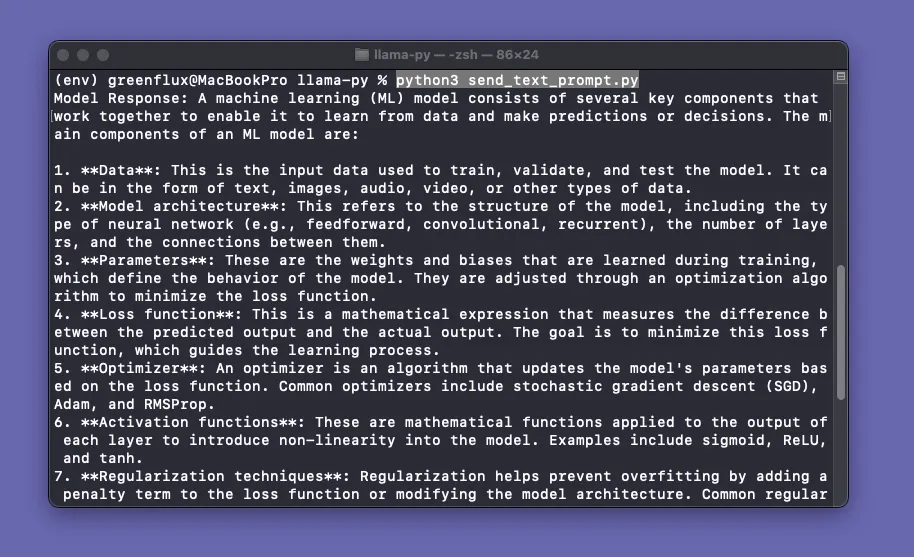
Ok, we have a working Python script to call the LLM and get a response. Now to add image processing and loop through a batch of images.
Image Prompts From Python
Next, we’ll create a new script for image prompting. We’ll need a function to convert an image to base64, and another function to loop through all images in the current folder.
Start out by adding a few images to the same folder as the python scripts. For this example, I’ll be using a screenshot from the Ollama GitHub repo that contains a table, and a hand-written note.
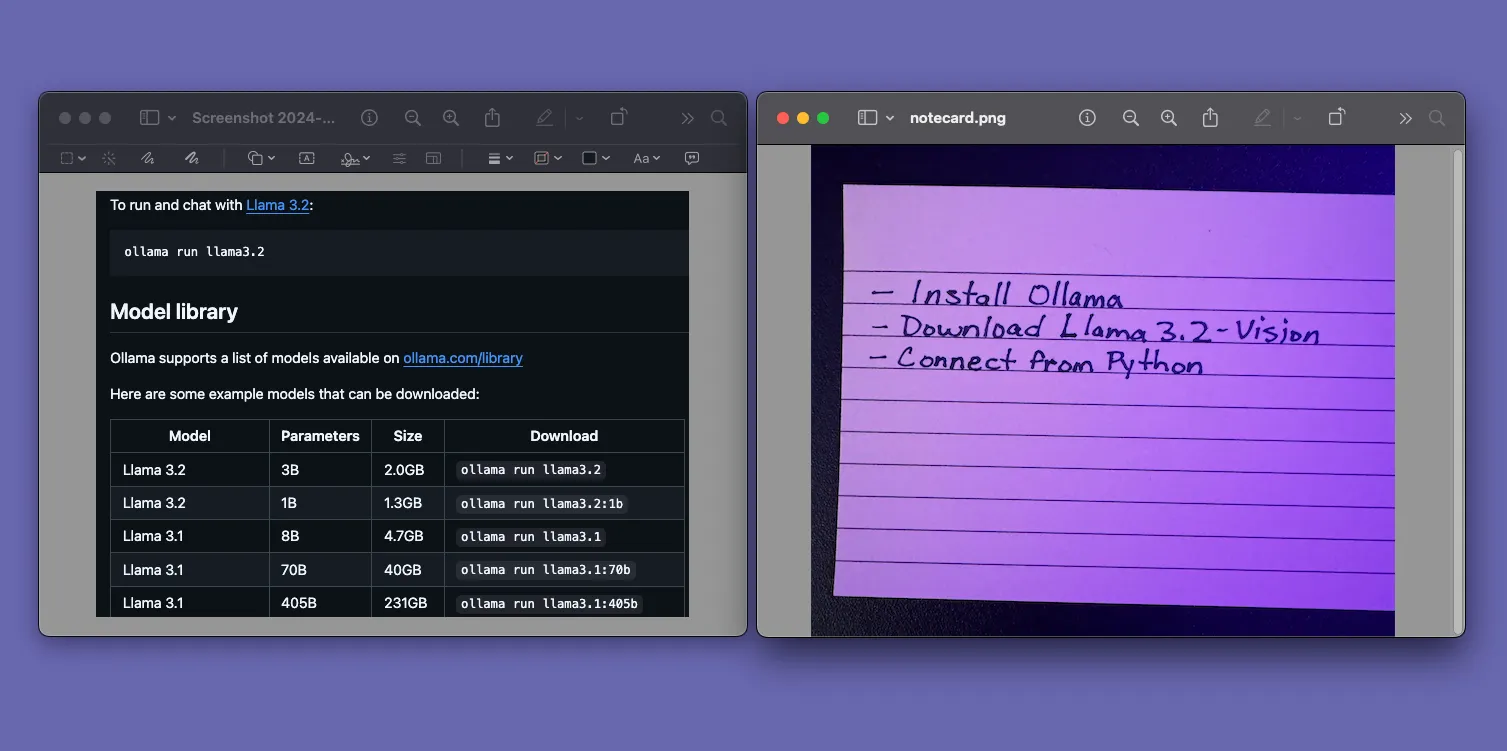
Then create a new script named image_to_text.py with the following script:
from pathlib import Path
import base64
import requests
def encode_image_to_base64(image_path):
"""Convert an image file to base64 string."""
return base64.b64encode(image_path.read_bytes()).decode('utf-8')
def extract_text_from_image(image_path):
"""Send image to local Llama API and get text description."""
base64_image = encode_image_to_base64(image_path)
payload = {
"model": "llama3.2-vision",
"stream": False,
"messages": [
{
"role": "user",
"content": (
"Extract all text from the image and return it as markdown.\n"
"Do not describe the image or add extra text.\n"
"Only return the text found in the image."
),
"images": [base64_image]
}
]
}
response = requests.post(
"http://localhost:11434/api/chat",
json=payload,
headers={"Content-Type": "application/json"}
)
return response.json().get('message', {}).get('content', 'No text extracted')
def process_directory():
"""Process all images in current directory and create text files."""
for image_path in Path('.').glob('*'):
if image_path.suffix.lower() in {'.png', '.jpg', '.jpeg', '.gif', '.bmp', '.webp'}:
print(f"\nProcessing {image_path}...")
text = extract_text_from_image(image_path)
image_path.with_suffix('.txt').write_text(text, encoding='utf-8')
print(f"Created {image_path.with_suffix('.txt')}")
process_directory()Save the script, and then test it out. It may take a few minutes, but you should end up seeing a new text file for each image in the directory.
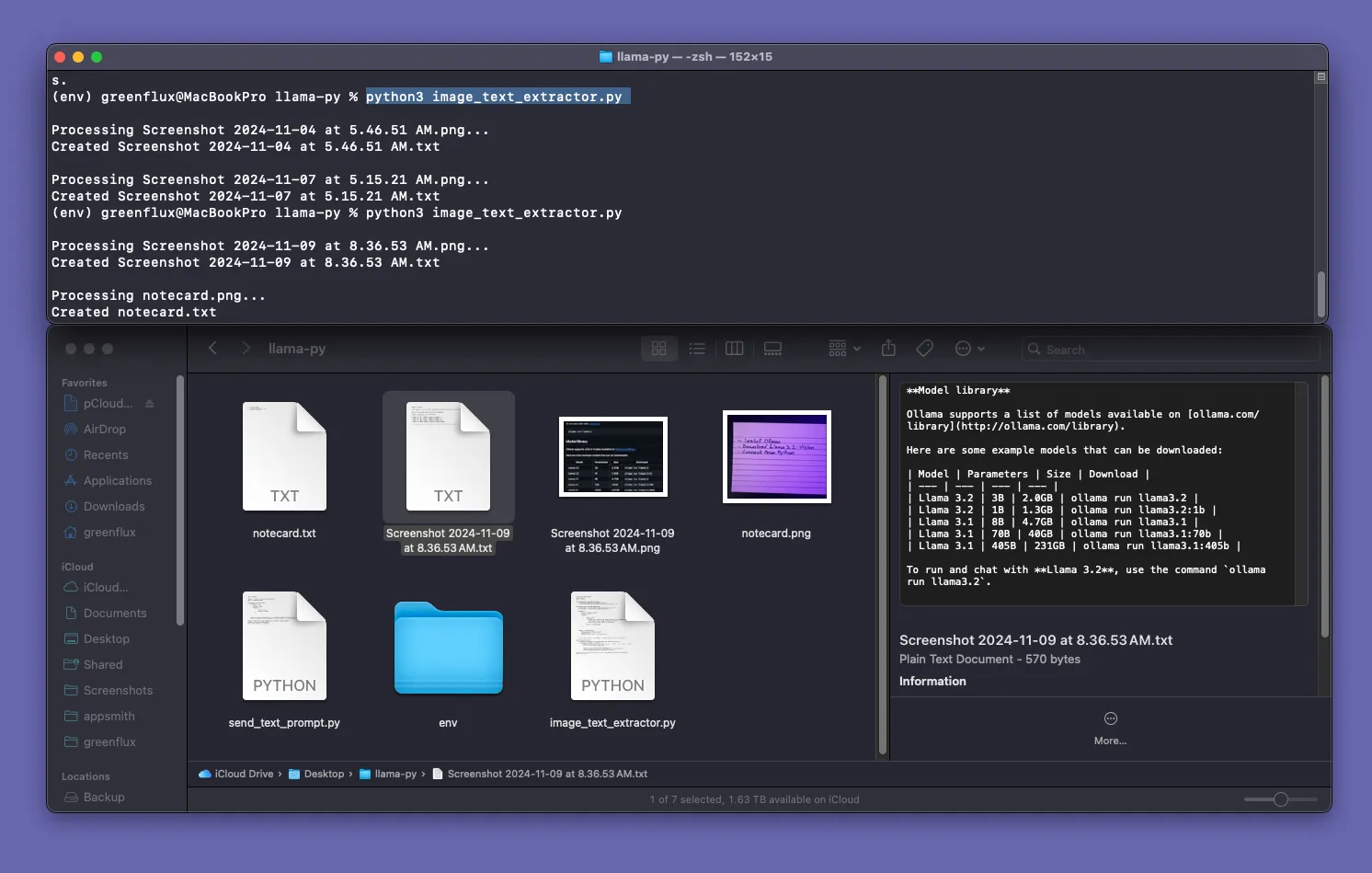
As you can see, the LLM was able to extract the table from the screenshot and save it as a Markdown table! It even got the hyperlink right! Here’s the exact Markdown, straight from the text file.
Model library
Ollama supports a list of models available on ollama.com/library.
Here are some example models that can be downloaded:
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 70B | 40GB | ollama run llama3.1:70b |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
To run and chat with Llama 3.2, use the command ollama run llama3.2.
And here’s the text file from the notecard:
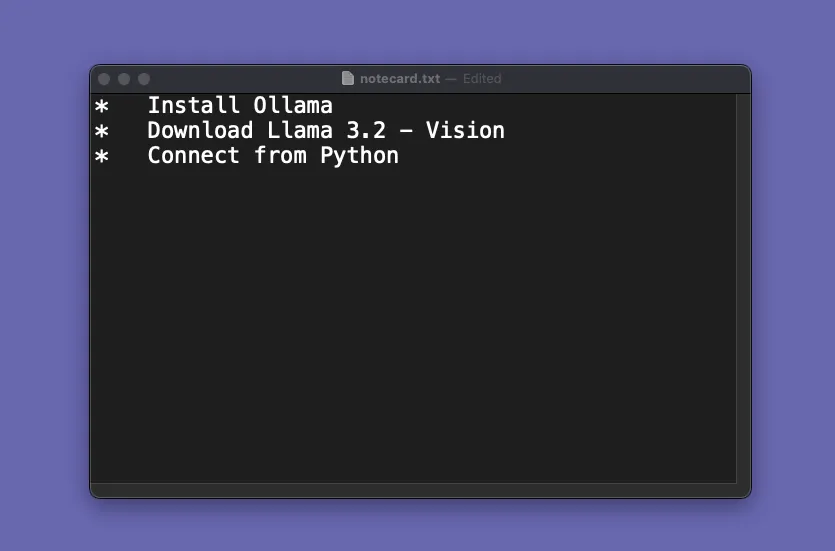
It really is amazing that an LLM this powerful can now run on a ~5 year old laptop, completely local, with no internet required!
Finishing Touches
Lastly, we can add in type safety and a class to define the config, so this script can be used on different directories with different setups.
from pathlib import Path
from dataclasses import dataclass
import base64
import requests
@dataclass
class LlamaConfig:
"""Configuration for Llama API."""
endpoint: str = "http://localhost:11434/api/chat"
model: str = "llama3.2-vision"
image_extensions: set[str] = frozenset({'.png', '.jpg', '.jpeg', '.gif', '.bmp', '.webp'})
def encode_image_to_base64(image_path: Path) -> str:
"""Convert an image file to base64 string."""
return base64.b64encode(image_path.read_bytes()).decode('utf-8')
def extract_text_from_image(image_path: Path, config: LlamaConfig) -> str:
"""Send image to local Llama API and get text description."""
base64_image = encode_image_to_base64(image_path)
content = (
"Extract all text from the image and return it as markdown."
"\nDo not describe the image or add extra text. "
"\nOnly return the text found in the image."
)
payload = {
"model": config.model,
"stream": False,
"messages": [
{
"role": "user",
"content": content,
"images": [base64_image]
}
]
}
response = requests.post(
config.endpoint,
json=payload,
headers={"Content-Type": "application/json"}
)
return response.json()['message'].get('content', 'No text extracted')
def process_directory(config: LlamaConfig) -> None:
"""Process all images in current directory and create text files."""
current_dir = Path('.')
for image_path in current_dir.glob('*'):
if image_path.suffix.lower() in config.image_extensions:
print(f"\nProcessing {image_path}...")
text = extract_text_from_image(image_path, config)
output_path = image_path.with_suffix('.txt')
output_path.write_text(text, encoding='utf-8')
print(f"Created {output_path}")
def main() -> None:
"""Main entry point."""
config = LlamaConfig()
process_directory(config)
if __name__ == "__main__":
main()Conclusion
With newer models like Llama3.2-vision, anyone can now run image-to-text LLMs locally and on regular consumer hardware, without the need for expensive GPUs. This opens up tons of new use cases, and avoids issues with privacy, security, and cost.
What’s Next?
From here you could add path variable instead of only running on the current directory, use different prompts for different directories, or even build a GUI to select images and view the LLM response.